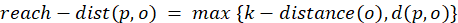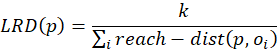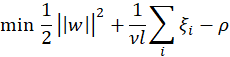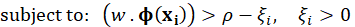First company to build an automated ML platform for the Arm Cortex-M0 and Cortex-M0+ processor
MOUNTAIN VIEW, Calif. (PRWEB) September 09, 2020
Qeexo, developer of an automated machine learning (ML) platform that accelerates the deployment of tinyML at the edge, today announces that its Qeexo AutoML platform now supports machine learning on Arm® Cortex®-M0 and Cortex®-M0+ processors, which power devices including sensors and microcontrollers from companies such as Arduino, Renesas, STMicroelectronics, and Bosch Sensortec.
The Arm Cortex-M0 processor is the smallest Arm processor available, and the Cortex-M0+ processor builds on Cortex-M0 while further reducing energy consumption and increasing performance. Qeexo is the first company to automate adding machine learning to a processor of this size. The Cortex-M0 and Cortex-M0+ processors are designed for smart and connected embedded applications, and are ideal for use in simple, cost-sensitive devices due to the lower power-consumption and ability to extend the battery life of critical use cases such as activity trackers.
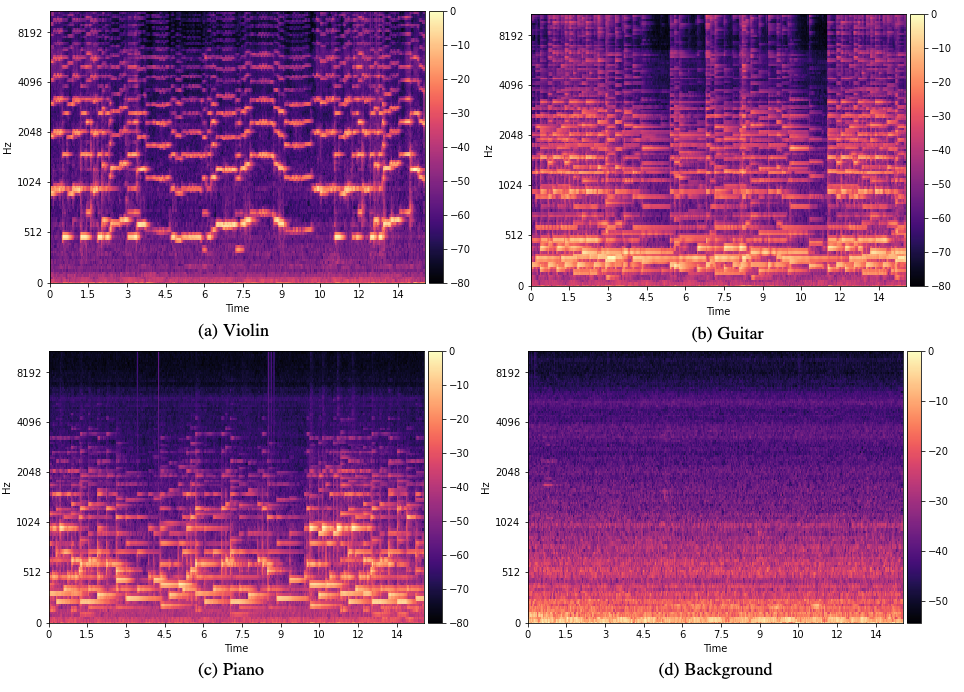
Machine learning models built with Qeexo AutoML are highly optimized and have an incredibly small memory footprint. Models are designed to run locally on embedded devices, ideal for ultra low-power, low-latency applications on MCUs and other highly constrained platforms.
“This integration delivers the advantages of data processing at the edge to even the smallest of devices,” said Sang Won Lee, co-founder and CEO of Qeexo. “Qeexo AutoML, combined with the accessibility of MCUs from companies such as Arduino, Renesas, STMicroelectronics, and Bosch Sensortec, greatly benefits application developers, who can now build smart hardware products with relative ease.”
The growing list of machine learning algorithms supported on Qeexo AutoML currently include: GBM, XGBoost, Random Forest, Logistic Regression, Decision Tree, SVM, CNN, RNN, CRNN, ANN, Local Outlier Factor, and Isolation Forest. Several hardware platforms from Arduino, Renesas, and STMicroelectronics work with Qeexo AutoML out-of-the-box.
Supporting Partner Quotes
Arm
“Today even the smallest devices can contain some layer of artificial intelligence and machine learning. The Cortex-M0 and Cortex-M0+ processors pack high performance with very low power consumption, and the added support of the Qeexo AutoML platform enables application developers to easily add intelligence to small devices such as wearables, making a world of one trillion intelligent devices a closer reality.”
— Steve Roddy, Vice President of Product Marketing, Machine Learning Group of Arm
Arduino
“Arduino is on a mission to make machine learning simple enough for anyone to use. We’re excited to partner with Qeexo AutoML to accelerate professional embedded ML development by guiding users to the optimal algorithms for their application. Combined with Arduino Nano 33 IoT, users can quickly create smart IoT sensors that can perform analytics at the edge, minimize communication, and maximize battery life.”
– Dominic Pajak, VP Business Development, Arduino
Bosch
“Bosch Sensortec and Qeexo are collaborating on machine learning solutions for smart sensors and sensor nodes. We are glad that Qeexo’s AutoML has added support for Cortex-M0 families, to which Bosch Sensortec’s smart sensors like BMF055 belongs. We are excited to see more applications made possible by combining the smart sensors from Bosch Sensortec and AutoML from Qeexo.”
– Marcellino Gemelli, Director of Global Business Development at Bosch Sensortec
Renesas
“Renesas and Qeexo collaborated on the design of a new RA-Ready sensor board: the RA6M3 ML Sensor Module. Equipped with various motion and environmental sensors and enhanced with Qeexo AutoML, this sensor module is the perfect reference platform for developing intelligent machine learning applications.”
– Kaushal Vora, Director of Strategic Partnerships & Global Ecosystem at Renesas
STMicroelectronics
“Qeexo AutoML recently added support for our STWIN industrial platform, which features embedded industrial-grade sensors and an ultra-low-power microcontroller for vibration analysis. By automating the development of ML solutions for advanced industrial IoT applications such as condition monitoring and predictive maintenance, Qeexo AutoML eases the usability of our products.”
– Pierrick Autret, Product Marketing Engineer at STMicroelectronics
###
About Qeexo
Qeexo is the first company to automate end-to-end machine learning for embedded edge devices (Cortex-M0-to-M4 class). Our one-click, fully-automated, Qeexo AutoML platform allows customers to leverage sensor data to rapidly build machine learning solutions for highly constrained environments with applications in industrial, IoT, wearables, mobile, automotive, and more.
Delivering high performance, solutions built with Qeexo AutoML are optimized to have ultra-low latency, ultra-low power consumption, and an incredibly small memory footprint. As billions of sensors collect data on every device imaginable, Qeexo can equip them with machine learning to discover knowledge, make predictions, and generate actionable insights.
Spun out of Carnegie Mellon University, Qeexo is venture-backed and headquartered in Mountain View, CA, with offices in Pittsburgh, Shanghai, and Beijing. To learn more, visit https://qeexo.com.