https://newsroom.st.com/zh/media-center/press-item.html/t4378.html
English version: LINK

https://newsroom.st.com/zh/media-center/press-item.html/t4378.html
English version: LINK

Finding new tech often means looking at startups. To support this critical aspect of the tech industry, Arm launches its “Startup Day” event. What is it, and what were some key takeaways?
Read the full article here: https://www.allaboutcircuits.com/news/arms-startup-day-shows-its-support-for-future-hardware-startups/

The dream of every developer is to be able to write code once and deploy everywhere. This allows for smaller teams to deploy more reliable products to a wider variety of users. Unfortunately, due to the numerous different operating systems with varying underlying kernels and user interface APIs, this often turns into a nightmare for developers.
Interpreted languages like Python in theory are great for cross platform code deployment. There are interpreters available for nearly any platform in existence. However, in a number of crucial ways, they fall short. First is the relative difficulty in protecting intellectual property. Because the code is not compiled, it is viewable to anyone in plain text. This requires techniques such as obfuscation or Cython compilation, both of which make debugging and deployment very complicated. Even semi-compiled languages such as Java can suffer from this problem.
Another major issue with shipping interpreted code to end users is the installation size. Shipping the python interpreter, pip, a number of pip packages, and the code can easily exceed a gigabyte on disk for even a simple application. Electron suffers from similar issues, having to bundle an entire Chromium install. This often results in subpar apps that love to consume memory.
Finally, dependency management on end users’ machines tends to be very unreliable with Python. If the code a developer is shipping relies on a specific package version (for example, Tensorflow 2.4.2), an install script attempting to install that package may encounter a version conflict. The script at this point must make the decision to abort or overwrite the user’s existing package. Both of these result in an extremely poor user experience. Packaging tools such as pipenv attempt to solve this, but this assumes that the user has the tool installed and that the version the user has installed matches that of the install script. Another way to solve this is to create an entirely separate Python install on the user’s machine, but this takes up unnecessary space and is still not immune to reliability issues and version conflicts. Additionally, the requirement of an internet connection is a concern for customers whose internet access may be limited or restricted for security reasons.
Compiled languages are an alternative to interpreted languages that are able to fulfil the requirements of intellectual property protection, small installation size, dependency management, and reliability. Below we consider a few:
C/C++
Pros
Cons
GO
Pros
Cons
Rust
Pros
Cons
Swift was originally developed to run on Apple platforms only. In 2016, Linux support was added. Since then, a large number of Swift packages have been designed to be compatible with both operating systems. In 2020, Windows support was added, completing support for the trio of major operating systems. For Qeexo, Swift ticked all the boxes. It is a modern language with features like type safety, optionals, generics, and a useful standard library, while also being cross platform, reliable, producing relatively small binaries, and protecting intellectual property. Additionally, with easy bindings into C code, it is easy to write code that interacts with well-tested, cross-platform libraries such as libusb.
Moving from Qeexo’s existing Python-based desktop client to one written purely in Swift has taken the installer size down from 108MB to 18MB, the install time from 57 seconds to 13 seconds, and from 830MB on disk to 58MB on disk. Additionally, the reliability of the installer and first-launch experience has improved substantially, with no dependency issues occurring because of lack of internet, version conflicts, and bad Python installs.
Thanks to a robust standard library, many of the operations required for our application such as network requests, JSON serialization, error handling, etc., simply work no matter which platform the code is running on. However, for complex tasks like USB device communication or WebSocket servers, more complex techniques were required. Libraries such as SwiftSerial or Vapor exist but are only supported on macOS and Linux due to the relatively new support of Swift on Windows. Rather than attempting to create a reliable WebSocket server or USB interface code from scratch on Windows in Swift, it was easier to hook into C libraries such as libwebsocket and libusb. Using a simple Swift package and module map (for example: https://github.com/NobodyNada/Clibwebsockets), Swift is easily able to pick up statically-linked libraries or dynamically-linked libraries (.dylib on Mac, .so on Linux, and .dll on Windows), and provide them with Swift syntax after a simple module import. These libraries are already cross-platform, so the work is already done. It only requires integrating a build script for the library into the overall compile process.
Using these techniques, very few locations required #if os() checks in our code. These included paths for log locations, paths for compiler flags in the package file, and USB path discovery. Everything else works the same across all operating systems.
As of the time this blog was published, Swift has only been available on Windows for less than a year. This means that resources such as Stackoverflow questions and libraries designed for Swift on Windows are sparse. Everything has to be built from scratch, discovered in the documentation, integrated from a C library, or discovered by looking at the Swift language source code. This will improve over time, but for the moment, cross-platform Swift programming can be a bit daunting for new users. For example, Alamofire, a very popular networking library for Swift, did not support Windows nor Linux until very recently. Qeexo contributed patches to the open-source library to get it into a working state.
Another issue is that Swift is not considered ABI-stable on Windows nor Linux yet. This means that all apps have to bundle the Swift runtime, rather than being able to take advantage of shared libraries. The library is not overly bloated, so this is not a major concern, but it is still a consideration.
Finally, even though Swift does run cross-platform, often times special considerations have to be made. For example, the function sleep() is not part of the Swift standard library. It comes from POSIX. This means that code using the function will not compile on Windows. Instead, helper functions using Grand Central Dispatch and semaphores had to be developed to simulate a sleep function. In addition, UI libraries are not standardized. macOS uses Cocoa, Windows uses WinUI/WPF, and Linux uses Xlib. Swift is capable of interacting with all 3 APIs, but all code will require #if os() checks and the code will be different per OS. As a result, Qeexo chose to write small wrapper apps in the OS’s preferred language in Swift/C#, then spawn the cross-platform Swift core as a secondary process. An added benefit is that the helper app is able to watch the subprocess for crashes and alert the user in a seamless fashion.
Thanks to an active community, a group dedicated to Swift on the server, and the backing of one of the largest technology companies on the planet (Apple), cross-platform Swift has a bright future. Eventually, SwiftUI might even allow for truly cross-platform UI development. In the meantime, Swift has allowed Qeexo to deploy a reliable and compact app that protects intellectual property and is truly cross-platform.

Anyone can now build smarter sensors using Qeexo and STMicroelectronics sensors: This is a cool example of ML at the edge. Chip vendor ST Microelectronics is working with Qeexo, a startup that builds software to easily train and generate machine learning algorithms, to ensure that its sensors will easily work with Qeexo software.
Read the full article here: https://staceyoniot.com/iot-news-of-the-week-for-july-9-2021/
Machine learning developer Qeexo and semiconductor STMicroelectronics have teamed up to allow STMicro’s machine learning core sensors to leverage Qeexo’s AutoML automated machine learning platform that accelerates the development of tinyML models for edge devices.
Read the full article here: https://www.fierceelectronics.com/iot-wireless/qeexo-adds-automl-to-stmicro-mlc-sensors-to-speed-tinyml-iiot
Qeexo, developer of the Qeexo AutoML automated machine-learning (ML) platform, and STMicroelectronics have announced the availability of ST’s machine-learning core (MLC) sensors on Qeexo AutoML.
Read the full article here: https://www.newelectronics.co.uk/electronics-news/iot-machine-learning-capable-motion-sensors/238717/

Qeexo and STMicroelectronics Speed Development of Next-Gen IoT Applications with Machine-Learning Capable Motion Sensors
Mountain View, CA and Geneva, Switzerland, July 7, 2021
Qeexo, developer of the Qeexo AutoML automated machine-learning (ML) platform that accelerates the development of tinyML models for the Edge, and STMicroelectronics (NYSE: STM), a global semiconductor leader serving customers across the spectrum of electronics applications, today announced the availability of ST’s machine-learning core (MLC) sensors on Qeexo AutoML.
By themselves, ST’s MLC sensors substantially reduce overall system power consumption by running sensing-related algorithms, built from large sets of sensed data, that would otherwise run on the host processor. Using this sensor data, Qeexo AutoML can automatically generate highly optimized machine-learning solutions for Edge devices, with ultra-low latency, ultra-low power consumption, and an incredibly small memory footprint. These algorithmic solutions overcome die-size-imposed limits to computation power and memory size, with efficient machine-learning models for the sensors that extend system battery life.
“Delivering on the promise we made recently when we announced our collaboration with ST, Qeexo has added support for ST’s family of machine-learning core sensors on Qeexo AutoML,” said Sang Won Lee, CEO of Qeexo. “Our work with ST has now enabled application developers to quickly build and deploy machine-learning algorithms on ST’s MLC sensors without consuming MCU cycles and system resources, for an unlimited range of applications, including industrial and IoT use cases.”
“Adapting Qeexo AutoML for ST’s machine-learning core sensors makes it easier for developers to quickly add embedded machine learning to their very-low-power applications,” said Simone Ferri, MEMS Sensors Division Director, STMicroelectronics. “Putting MLC in our sensors, including the LSM6DSOX or ISM330DHCX, significantly reduces system data transfer volumes, offloads network processing, and potentially cuts system power consumption by orders of magnitude while delivering enhanced event detection, wake-up logic, and real-time Edge computing.”
About Qeexo
Qeexo is the first company to automate end-to-end machine learning for embedded edge devices (Cortex M0-M4 class). Our one-click, fully-automated Qeexo AutoML platform allows customers to leverage sensor data to rapidly build machine learning solutions for highly constrained environments with applications in industrial, IoT, wearables, automotive, mobile, and more. Over 300 million devices worldwide are equipped with AI built on Qeexo AutoML. Delivering high performance, solutions built with Qeexo AutoML are optimized to have ultra-low latency, ultra-low power consumption, and an incredibly small memory footprint. For more information, go to www.qeexo.com.
About STMicroelectronics
At ST, we are 46,000 creators and makers of semiconductor technologies mastering the semiconductor supply chain with state-of-the-art manufacturing facilities. An independent device manufacturer, we work with more than 100,000 customers and thousands of partners to design and build products, solutions, and ecosystems that address their challenges and opportunities, and the need to support a more sustainable world. Our technologies enable smarter mobility, more efficient power and energy management, and the wide-scale deployment of the Internet of Things and 5G technology. Further information can be found at www.st.com.
For Press Information Contact:
Lisa Langsdorf
GoodEye PR for Qeexo
Tel: +1 347 645 0484
Email: lisa@goodeyepr.com
Michael Markowitz
Director Technical Media Relations
STMicroelectronics
Tel: +1 781 591 0354
Email: michael.markowitz@st.com

This blog post is a companion to my talk at tinyML Summit 2021. The talk and this blog overlap in some content areas, but each also has unique content that complements the other. Please check out the video if you are interested.
For embedded applications, size matters. Compared to CPUs, embedded chips are much more constrained in various ways: in memory, computation ability, and power. Therefore, small models are not just desirable, they are essential. We at Qeexo have asked ourselves: how can we make small, high-performance models? We have dedicated resources to answering this question, and we have made advances in compressing many of our model types. For some of those model types, compression has been achieved through quantization.
For our purposes here, the following is what we mean when we “quantize” a machine learning model:
Change the data types used to encode the trained-model parameters from larger-byte data types to smaller-byte data types, while retaining the behavior of the trained model as much as possible.
By using smaller-byte data types in place of larger-byte data types, the quantized machine learning model will require fewer bytes for its encoding and will therefore be smaller than the original.
In our experience at Qeexo we have found that tree-based models often outperform all other model types when the models are constrained to be small in size (e.g. < 100s KB) or when there is relatively little available data (e.g. < 100,000 training examples). Both of these conditions are often true for machine learning problems targeting embedded devices.
As stated above, due to the memory constraints on the device the models must be small. For example, the Arduino Nano 33 BLE Sense has 1 MB CPU flash memory and 256 KB SRAM. These resources are shared among all programs running on the device, and the available resources for a machine learning model are going to be significantly smaller than the full amounts. The actual resources available for the machine learning model will vary by use-case, but a reasonable estimate as a starting point is that perhaps half of the resources can be used by the machine learning model.
As for the amount of available data, several factors tend to lead to relatively little available data
for machine learning models targeting embedded devices:
Because tree-based models tend to perform well, and are often the superior model type, under the constraints above, they are well-suited for embedded devices. For this reason, we are interested in using them for our own embedded applications and in offering them as part of our suite of models for use in Qeexo AutoML.
Encodings of trained tree-based models lead to parameters and data that fall into 3 categories:
The first two categories above, leaf values and feature thresholds, provide the possibility for quantization. At Qeexo, we have implemented quantization for these parameter types. While there has been research on and implementations for quantization of neural-network-based models, we aren’t aware of similar research and implementations for tree-based models; we have done our own research and created an implementation for quantization for tree-based models.
In our experience, the strongest constraint placed on tree models by embedded chips is the flash size. By quantizing the model, the number of bytes needed to encode the model is smaller. This allows tree-based models to fit on the device that would not have fit without quantization, or in the case of smaller tree-based models, quantizing them leads to more room on the embedded device for other functionality.
Reducing the size of the data types used to encode the trained model parameters leads to some loss of information for those parameters, and this leads to a difference in behavior between the original model and the quantized version. The difference in behavior is often small, but if it is not small enough it can sometimes be made smaller by giving up some compression gains (i.e. increase the size of the quantized data type; in the “Leaf Quantization Example” below, one could use the 2-byte uint16 instead of the 1-byte uint8 as the quantized data type. This would make the quantized model more faithful, but also bigger).
There is another factor that can lead to a reduction in compression gains when quantizing tree-based models: depending on the tree model in question and on the quantization type, it may be necessary to store some of the parameters of the quantization transformation along with the model on-device. This is because in some cases it is necessary to de-quantize one or more quantized parameters during inference to correctly produce predictions or prediction probabilities. Storing these transformation parameters costs bytes on-device, which eats into the compression gains. The number of transformation parameters required depends strongly on the quantization type. For example, when using a simple quantization scheme such as an affine transformation (a shift followed by a rescaling), the leaf quantization transformation parameters are 2 floating-point parameters if all leaf values are quantized together. On the other hand, for feature threshold quantization, each feature used in the model requires a stored transformation, which leads to 2 floating-point parameters per used feature. The former costs very little (a few bytes), and is applicable to any tree implementation with floating-point leaf values or integer leaf values when the values are large enough. The latter can cost many bytes depending on the number of features, and should only be considered for large models where the number of splits per feature across the tree-based model is large enough to absorb the cost of storing the feature threshold quantization parameters.
To illustrate the gains and costs of tree model quantization, we’ll consider an example using leaf quantization. For our example, consider a “letter gesture” problem, a benchmark problem we use often at Qeexo. The setup:
sklearn.ensemble.GradientBoostingClassifier with default parameters (mostly)| true/pred | A | NOISE | O | S | V |
|---|---|---|---|---|---|
| A | 133 | 0 | 2 | 0 | 2 |
| NOISE | 0 | 543 | 0 | 0 | 0 |
| O | 0 | 0 | 98 | 1 | 0 |
| S | 3 | 1 | 21 | 95 | 0 |
| V | 8 | 0 | 0 | 0 | 58 |
| Value | Number | Encoding | Bytes |
|---|---|---|---|
| Leaves | 3595 | float32 | 14380 |
| Feature Thresholds | 3095 | float32 | 12380 |
| Tree Structure | various uint | 12884 | |
| Total | 39644 |
The breakdown in bytes will generally follow this pattern, with the leaves and feature thresholds making up about 1/3 of the total model size each (with leaves always a bit more; for each tree there is always one more leaf than the number of splits), with the tree structure making up the remaining 1/3.
To quantize the model, we need to choose what parameters to quantize and the quantization transformation. For this example, we are quantizing the leaves only, and let us quantize them via an affine transformation (a shift followed by a rescaling) down to 1-byte uint8 values. With this transformation, we will reduce the bytes required to encode the leaves by a factor of 4. For this tree implementation, we do need to retain one of the leaf quantization parameters on-device for use during inference, but this costs very little: a single 4-byte float32. This value is used to rescale the accumulated leaf values back into the un-quantized space before applying the softmax function to compute the by-class probabilities.
| true/pred | A | NOISE | O | S | V |
|---|---|---|---|---|---|
| A | 133 | 0 | 2 | 0 | 2 |
| NOISE | 0 | 543 | 0 | 0 | 0 |
| O | 0 | 0 | 98 | 1 | 0 |
| S | 3 | 1 | 24 | 92 | 0 |
| V | 8 | 0 | 0 | 0 | 58 |
| Value | Number | Encoding | Bytes |
|---|---|---|---|
| Leaves | 3595 | uint8 | 3595 |
| Feature Thresholds | 3095 | float32 | 12380 |
| Tree Structure | various uint | 12884 | |
| Leaf quant params | 1 | float32 | 4 |
| Total | 28863 |
sklearn.metrics.log_loss) has increased a small amount: from 0.0996 for the un-quantized model to 0.0998 for the quantized model.The quantization procedure effectively introduces some small amount of noise into the model parameters. We expect that this will on average degrade performance, and this is seen here in this particular example: quantizing the model led to slightly lower performance on the held-out data.
So, at the cost of a slight loss in model fidelity we have reduced the overall model size by 27%. The trade-off observed in this example matches our experience at Qeexo with quantized models generally: a slight loss in fidelity with a significant reduction in model size. In the context of an embedded device, this amount of reduction is often a worthwhile trade-off.
In this post, we have discussed why compressed tree-based models are useful models to consider for embedded machine learning applications, and have focused on a particular compression technique: quantization. Quantization can compress models by significant amounts with a trade-off of slight loss in model fidelity, allowing more room on the device for other programs.
The quantized tree-based models are among the model types available for use in Qeexo AutoML, an end-to-end automated machine learning pipeline targeting embedded devices. To learn more and try out Qeexo AutoML for free, head to https://qeexotdkcom.wpengine.com/ml-platform/.
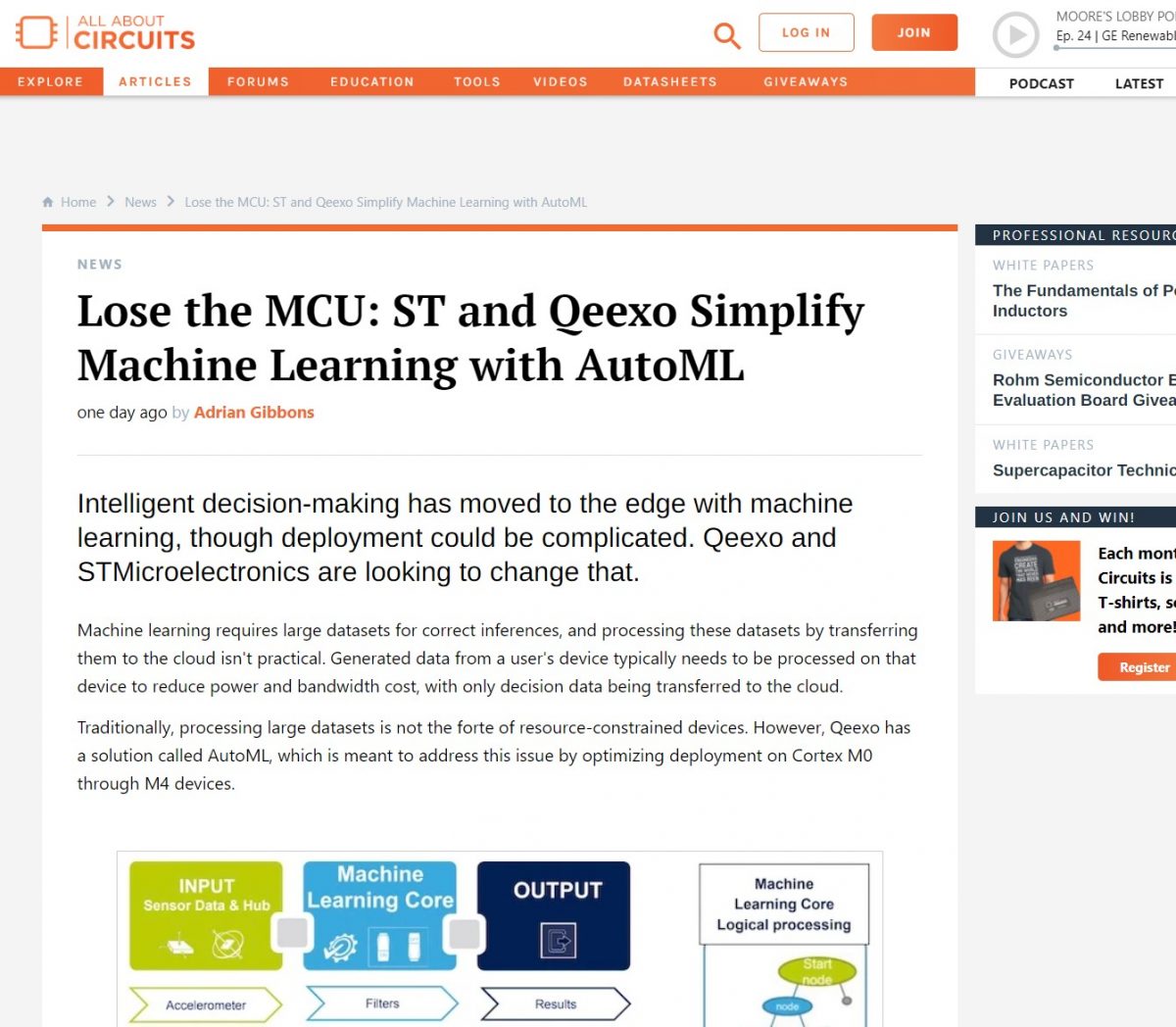
Intelligent decision-making has moved to the edge with machine learning, though deployment could be complicated. Qeexo and STMicroelectronics are looking to change that.
Read the full article here: https://www.allaboutcircuits.com/news/lose-the-mcu-st-and-qeexo-simplify-machine-learning-with-automl/
Company also debuts the Qeexo Model Converter to optimize customers’ existing machine learning models for the Edge
MOUNTAIN VIEW, CALIF. (PRWEB) MAY 18, 2021
Qeexo, developer of an automated machine learning (ML) platform that accelerates the development of tinyML models for the edge, today announced that it is working with STMicroelectronics to enable developers to create machine learning models for ST’s Machine Learning Core (MLC) sensors, so that inferences can run right on the sensor, without the need for a microcontroller. This feature will be available to users in Q2.
Traditionally, due to limited computation power, memory size, and battery life, building machine learning solutions for edge devices had been challenging. Qeexo AutoML solves this. Its one-click, fully automated platform allows customers to rapidly build machine learning solutions for edge devices using sensor data. By moving machine learning to embedded processors and now sensors on edge devices, developers can improve privacy, latency, and availability.
“Qeexo continues to demonstrate technical leadership in the embedded machine learning space by automating machine learning on tiny, resource-constrained devices – this time, on a Machine Learning Core sensor, independent from an MCU,” said Sang Won Lee, CEO of Qeexo. “For use cases that can benefit from machine learning, but do not have access to MCUs due to cost, power, latency, or infrastructure constraints, there are significant advantages to running machine learning on the sensor, including cost and power savings.”
“Many IoT solutions developers are looking to easily add embedded machine learning to their very low power applications and need help to bridge the gap from concept to prototype to production,” said Simone Ferri, MEMS Sensors Division Director, STMicroelectronics. “We put MLC in our sensors to reduce system data transfer volumes and offload network processing. Qeexo AutoML can help unlock the benefits of inherently low-power sensor design, advanced AI event detection, wake-up logic, and real-time Edge computing.”
Qeexo also announced that it is launching a model converter that can take machine learning models in the ONNX format to optimize them for embedded devices. For customers who already have a machine learning team, and who have worked on and have existing machine learning models, they can use the Qeexo Model Converter to make them smaller and more optimized for embedded devices. The technology will also make it easier for developers who want to compare the performance of their hand-built models against the models automatically created with Qeexo AutoML.
In addition, Qeexo is now offering a machine learning consulting service to help clients jump-start their projects. Qeexo will first work with clients to develop and deploy commercial-ready machine learning solutions, then tailor Qeexo AutoML to fit customer needs. Qeexo will provide the knowledge transfer necessary for client teams to continue to use Qeexo AutoML for current and future projects.
About Qeexo
Qeexo is the first company to automate end-to-end machine learning for embedded edge devices (Cortex M0-M4 class). Our one-click, fully-automated Qeexo AutoML platform allows customers to leverage sensor data to rapidly build machine learning solutions for highly constrained environments with applications in industrial, IoT, wearables, automotive, mobile, and more. Over 300 million devices worldwide are equipped with AI built on Qeexo AutoML. Delivering high performance, solutions built with Qeexo AutoML are optimized to have ultra-low latency, ultra-low power consumption, and an incredibly small memory footprint.
For more information, go to www.qeexo.com.